Data is extremely important to us at Lumosity – as custodians of the world’s largest cognitive training database, we feel a sense of responsibility toward not only our subscribers, but to the world at large. With this in mind, our engineering organization places durability and operational simplicity in high regard. In the eventual case of system or component failure, we do our absolute best to ensure that we won’t lose data, and this often requires thinking pessimistically about worst-case scenarios, edge cases, and unlikely probabilities.
Our web and mobile apps are heavily instrumented to help us track engagement and make smarter choices about the design of our apps. The core of our business is cognitive science, which means that we also record, process, warehouse, and make available time-series game play data over billions of game plays. Instrumenting your application for simple funnel analysis isn’t so hard, but as traffic and use cases for streaming data–especially game play data–exploded, we struggled with scaling and feature delivery speed.
In 2016, we made the migration from our own event server and simple stream processing framework to a Apache Kafka cluster fed by FluentD and consumed using KStreams, Spark Streaming, as well as some custom Akka applications. We’re pretty happy with our current architecture, but it was a journey.
In-House Systems
Our earliest efforts were fairly simple: pushing events through Redis pub/sub from Rails and ingesting them from a Node server with simple processors written in Javascript. Though it wasn’t the fault of the tools, no one was particularly happy with this solution: it became clear fairly quickly that in order to keep up with load we’d need to invest serious effort into technologies that weren’t otherwise in our wheelhouse. Our next iteration was built in-house using Ruby, and handling transactions at the file level; this leveraged experience we already had. App server HTTP requests were handled by a single process, and so we bound process to its own append-only file, which was rotated out when crossing a time- or size-boundary. A local event system agent on the host would then be responsible for the rotated-out file, individually coordinating its transfer to the more-centralized Event System. This Event System in turn had its own S3 collators and simple stream processors, which operated line-by-line, file-by-file via a dispatcher.
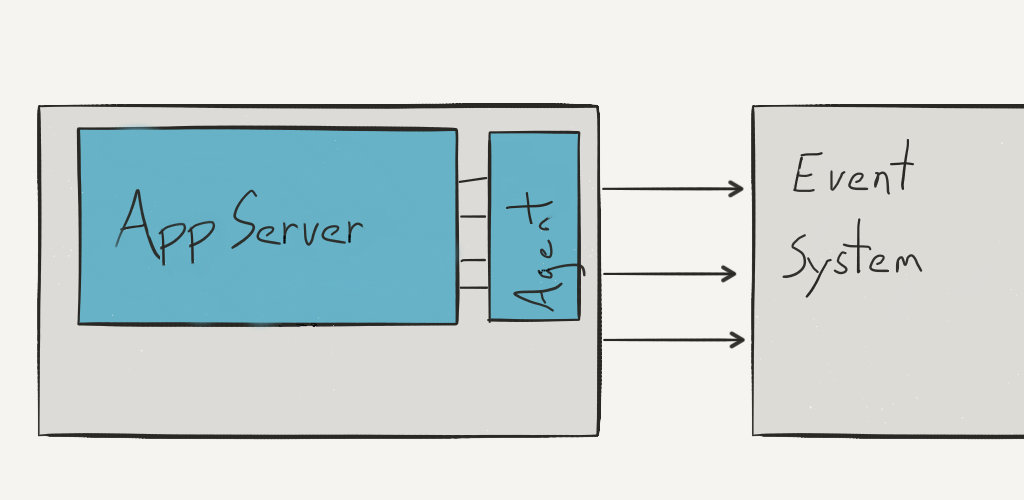
This was able to handle our peak load at the time as well as most of our processing needs, and we were able to reason effectively about durability guarantees by way of the file system, which was great. However, expertise on our own Event System wasn’t something we could hire for, nor was it pluggable into existing, robust stream processing systems like Storm/Heron, Spark Streaming, or Flink. This was in early 2016, and it was clear that Kafka was a big player for coordinating stream data across organizations, although we didn’t have any internal experience operating it, nor writing or integrating producers or consumers.
The Recent Past: Integrating Kafka
As mentioned in the intro, we take data durability extremely seriously. One of the more alluring aspects of the in-house system was that even if the Event System were to topple over with unexpected load, as long as we had app servers to handle traffic the app server hosts would continue buffering to their attached EBS volumes. At one point while conducting research for a post-mortem after an actual event system outage, we’d estimated that given sustained, 95th-percentile traffic we wouldn’t start running into data loss trouble for another 27 days. That’s obviously well outside any availability SLA we’d like to establish, but it still gave us some peace of mind.
This was a large factor in our minds when we were planning out the design of our new event architecture. Neither Data Engineering nor Production Engineering had experience with Kafka operations, so we knew we’d stumble at least a few times, and given the maturity of the data set, engineering team, and customer expectations, we needed be extremely mindful of potential service unavailability and data loss. The app servers are written in Ruby, and the Ruby/Kafka integration at the time didn’t feel robust enough to us to wait on writing to Kafka while responding to an HTTP request. We were most comfortable buffering data locally–even if EBS isn’t immediately local, it’s operated by AWS and represented one less moving part–so our options were either to write our own daemon that sat on each app server host and buffered to disk for periods of Kafka unavailability (which is how the old system acted when its single point of failure experienced downtime), or to look for a system or component that already existed.
We wound up choosing FluentD, but used it in a way that’s not the typical FluentD architecture: it was really designed to be the generic delivery medium for your system, which is really what we were using Kafka for. Still, via buffer plugins and the right combination of settings, it’s able to do exactly what we wanted when things go wrong without getting much in the way of writing to Kafka under normal circumstances.
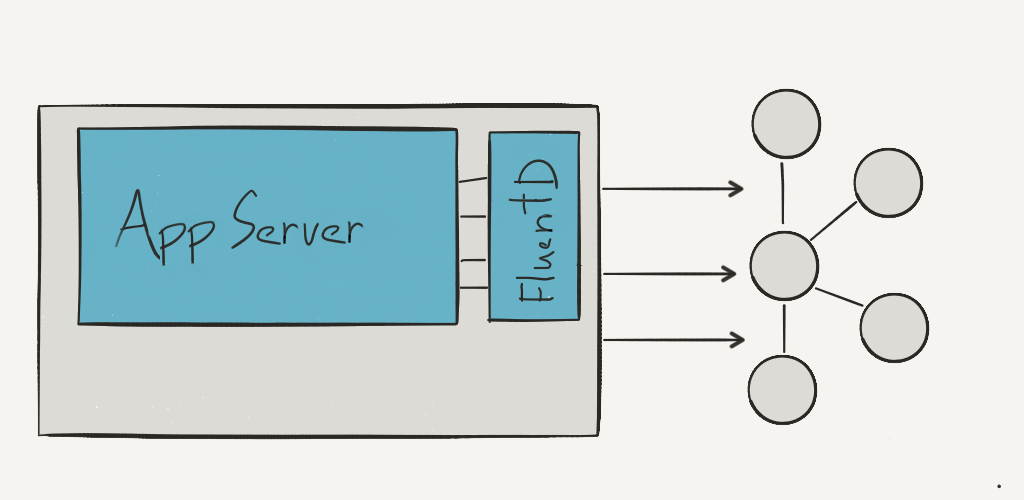
There are some tradeoffs, of course. It’s going to introduce latency, even when nothing goes wrong. We decided this was fine for us, as the vast majority of events are for offline analysis, and even for events which feed back into the user experience, end-to-end latency is well below anything on the order of human interaction time. FluentD is written in Ruby, so we didn’t entirely avoid the issue of maturity in Ruby/Kafka. We were pretty skeptical overall until the FluentD Kafka plugin was updated to use ruby-kafka, over the Kafka 0.8-only gem, Poseidon.
Additionally, getting FluentD’s configuration settings correct was non-trivial. It was fairly easy to get data written to Kafka, almost out-of-the-box, but flush intervals, optimal buffer/chunk sizes, and forcing the FluentD writer to wait for ACKs from more than one Kafka broker were either not obvious, or required some level of trial-and-error. In total, we kept both the in-house system and FluentD/Kafka active for a period of several months. This may have been overkill, and the time wasn’t entirely spent tuning FluentD or our Kafka cluster, but it allowed us to pause integration and work on other projects while the new system was under active observation and receiving production load.
The Present: Integrating Kubernetes
We were able to get quite a bit of mileage out of the previous setup: it enabled our real-time Insights data pipeline feature, allowed us to sunset hand-spun technology in favor of F/OSS, and let us–by and large–sleep at night. However, the architecture was designed for hosts bootstrapped by Chef and running directly on EC2 nodes, and our Production Engineering team was concurrently spending most of their time building out our container-based strategy, based around Kubernetes. We never planned on moving Kafka or Zookeeper into containers, but the pairing of one App Server (made up of many Unicorn processes) to one FluentD server was something that was open for discussion.
The most natural transition from our EC2 setup would be to deploy FluentD on each host in Kubernetes as a DaemonSet. This would exploit the locality of services by only communicating with localhost to the buffering system, which was a property of our original two systems. Also, our Production Eng team was concerned that updates to FluentD would require us to rotate out entire hosts, instead of just rotating out containers. This held more weight for us than preserving service locality.
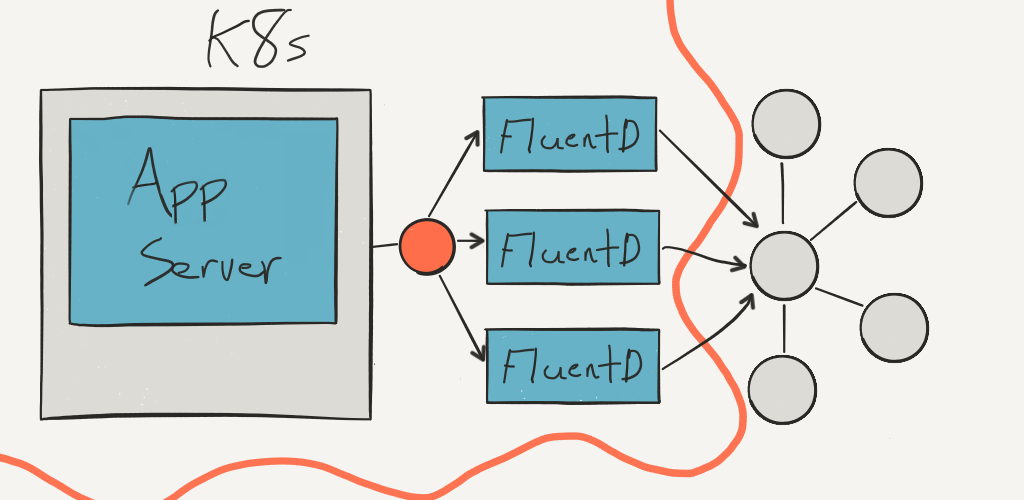
The architecture we settled on looks a lot more like what FluentD was designed for: services communicating with a remote FluentD server (in our case, managed and load-balanced by Kubernetes), which buffers as expected, then flushes to Kafka. Overall, we’re more comfortable with the high availability that running FluentD as a load-balanced service, leveraging Kubernetes to manage the uptime of that service, than we are with running–and being responsible for–everything on every node. Traffic from FluentD exits the Kubernetes sub-network and gets sent to Kafka, which is still running directly on EC2, as is Zookeeper.
Conclusions
At this point, we’re pretty happy with our event infrastructure–Kafka gives us the durability and low latency we wanted, fairly easy integration with systems we were using or want to use, and has a thriving community, in part through the participation of its primary sponsor, Confluent. We attribute the success of the endeavor in large part to the fact that we weren’t designing in anticipation of future load, but had to address it from the outset. It was also a big plus that we had the capacity to run the two systems in parallel for as long as we needed. This allowed us to learn how to operate Kafka, Zookeeper, and FluentD all at the same, while having relatively little impact on our internal or external users.
I’d like to thank David Boctor on the Data Engineering team, who designed and oversaw the transition from front to back, as well as Albert Dixon and Shaun Haber on the Production Engineering team, who were instrumental in the migration to Kubernetes.
If working on these sorts of systems at scale interests you, or if you’d just like to talk more about this architecture or or other data topics, please check out our open positions or reach out!