The Problem
Platforms like iOS and Android make it easy to tell which of your localization strings are currently in use - just do a bit of grepping or run a script and voilà!
Once you’ve identified which ones you’re using, you can remove any unused, crufty strings from your translation files and move on with your life.
However, due to Ruby’s dynamic nature and the fact that you can never tell what Rails is actually doing even under the best of circumstances, identifying unused strings is much more difficult. The static analysis that worked so well with iOS and Android projects won’t work for your Rails app.
Consider this ERB template. It lives in app/views/products/index.html.erb:
1
2
3
<div class="description">
<%= I18n.t('.description') %>: <%= @product.description %>
</div>
Under the hood, the i18n gem (which provides Rails’ localization implementation) fully qualifies .description into products.index.description. Because this qualification is done at runtime, static analysis (i.e. grepping) won’t be able to identify all the strings your app is currently using.
The problem is compounded by the fact that the key you pass to I18n.t is just a string, and can therefore be generated in any way the Ruby language allows, for example:
1
2
3
4
5
6
7
<div class="fields">
<% @product.attributes.each_pair do |attr, value|
<div class="<%= attr %>">
<%= I18n.t(".#{attr}") %>: <%= value %>
</div>
<% end %>
</div>
It’s probably bad practice to loop over all the attributes in your model and print them out. Hopefully though, this example illustrates the problem - namely that the I18n.t method can accept any string, including string variables, interpolated strings, and the rest. Unless your static analyzer is very, very clever, it won’t be able to tell you which of your localization strings are currently being used with any kind of reliability.
Ok, so what should I do about it?
So glad you asked.
The only foolproof way to collect information about the localization strings your app is using is during runtime. We have to find some way of hooking the I18n.t method in order to inspect the arguments passed to it.
Fortunately, a smart, generous open-source contributor has already done this for us in the form of the i18n-debug gem. This gem couldn’t be more straightforward to use. Simply include it in your Gemfile and add a callback in a Rails initializer:
1
2
3
4
I18n::Debug.on_lookup do |key, value|
# Do something with key and/or value.
# By default, they're logged to the console.
end
Great! So we’re done right? Not so fast.
You might want to know a bit more contextual information about the lookups, like:
- The URL of the request that caused the lookup.
- Where the
I18n.tmethod was called (probably some view or partial). - The current locale, i.e. the value of
I18n.locale.
Also, if you’re using the capable i18n-js gem, you’ll probably want to hook I18n.t calls in Javascript too.
Introducing the i18n-instrument gem
We built the i18n-instrument gem to annotate calls to I18n.t in Ruby/Rails and Javascript. It works by adding a piece of Rack middleware to your Rails app’s middleware stack. Whenever the I18n.t method is called, i18n-instrument will fire a callback and pass you some useful information, including the URL of the request, the place I18n.t was called in your code, and the current locale.
Configuring i18n-instrument is almost as easy as i18n-debug. Just add the gem to your Gemfile and stick the config in a Rails initializer:
1
2
3
4
5
6
7
I18n::Instrument.configure do |config|
config.on_record do |params|
# Params is a hash containing useful information, including:
# :url, :trace, :key, :locale, and :source.
# Source is either 'ruby' or 'javascript'.
end
end
From here, the possibilities are endless. You could log the information to the console, write it down somewhere useful, save it to a database, you name it.
At Lumos Labs, we decided to log the data to a series of CSV files so it would be easy to parse and store in a database later. Because i18n-instrument pushes itself onto your app’s rack middleware stack, every single request will pass through it. This means whatever you do in the on_record callback needs to be really fast - otherwise you could very negatively impact your app’s performance. We ruled out approaches that involved saving data to a database like MySQL or Redis because of the overhead associated with making any kind of network call. Saving the data to a CSV file is much lower cost and isn’t likely to significantly impact performance.
Here’s the essence of the code we ended up with. Note that the code opens a new CSV file for each individual process. We hoped doing so would avoid race conditions under Unicorn, which forks to create a number of child processes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
require 'csv'
require 'English'
I18n::Instrument.configure do |config|
# hash of process ids to open log file objects
log_files = {}
config.on_record do |params|
# open new log file for this process id if one isn't already open
log_files[$PROCESS_ID] ||= begin
log_file_name = "i18n-instrument-#{DateTime.now}_#{$PROCESS_ID}.csv"
CSV.open(log_file_name, 'w+')
end
log = log_files[$PROCESS_ID]
# write CSV entry by pulling fields out in a defined order
log << %i(url trace key source locale).map { |key| params[key] }
# force log to write entry to disk instead of buffering since the
# log files are only closed when the server dies or restarts
log.flush
end
end
Using the Lookup Data
After configuring, code-reviewing, and deploying, we let one of our app servers collect instrumentation data overnight. The next morning, the server had ~800mb of log data ready for analysis. A quick throwaway script parsed the CSV and threw it into a SQLite database (we used the excellent and lightweight Sequel library instead of ActiveRecord to access the database):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
require 'csv'
require 'sequel'
require 'sqlite3'
DB = Sequel.connect('sqlite://db.sqlite3')
unless DB.tables.include?(:instances)
DB.create_table(:instances) do
primary_key :id
String :url
String :trace
String :key
String :source
String :locale
index :id
index :key
end
end
DB[:instances].truncate
columns = %i(url trace key source locale)
source_idx = columns.index(:source)
key_idx = columns.index(:key)
files = Dir.glob('path/to/i18n-instrument-*.csv')
files.each do |file|
puts "Processing #{file}"
CSV.foreach(file).each_slice(500) do |slice|
slice.each do |fields|
# remove locale prefix for ruby instances
# (locale present as first path segment)
if fields[source_idx] == 'ruby'
fields[key_idx].sub!(/[^.]+\.(.*)/, '\1')
end
end
DB[:instances].import(columns, slice)
end
end
It was pretty easy then to pull out all the unique translation keys:
1
2
3
4
unique_keys = DB[:instances]
.select(:key)
.group(:key)
.map { |fields| fields[:key] }
Once we had indentified all the unique translation keys, we compared them to the keys in our en.yml file. The Rails YAML parsing is done by the abroad gem:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
require 'abroad'
file = 'path/to/app/config/locales/en.yml'
extractor = Abroad.extractor('yaml/rails').open(file)
keep = {}
extractor.extract_each do |key, value|
# only keep keys that we know are being used
keep[key] = value if unique_keys.include?(key)
end
# write the clean YAML file as en.clean.yml in the same directory
outfile = file.chomp(File.extname(file)) + '.clean.yml'
serializer = Abroad.serializer('yaml/rails')
serializer.from_stream(File.open(outfile, 'w+'), :en) do |serializer|
keep.each_pair do |key, value|
serializer.write_key_value(key, value)
end
end
That’s it! All unused keys have been removed from en.yml. It’s time for a thorough code review and a bunch of manual testing on a staging server.
It’s worth noting that this approach may not instrument all the strings your code is using, since certain code paths may not have been travelled while you were collecting data. Be careful you don’t inadvertently remove a string your app actually needs! Test, test, and then test again.
Other Cool Stuff You Can Do With Your Data
You may be wondering why we collected so much additional data - eg. the trace, locale, etc - only to ignore most of it. There are a number of other interesting things you can do with the data once you have it.
For example, it’s easy to see which locales are the most popular by grouping by locale:
1
2
3
4
result = DB[:instances]
.group_and_count(:locale)
.all
.sort { |a, b| b[:count] <=> a[:count] }
Here’s a graph of the results for lumosity.com (English excluded):
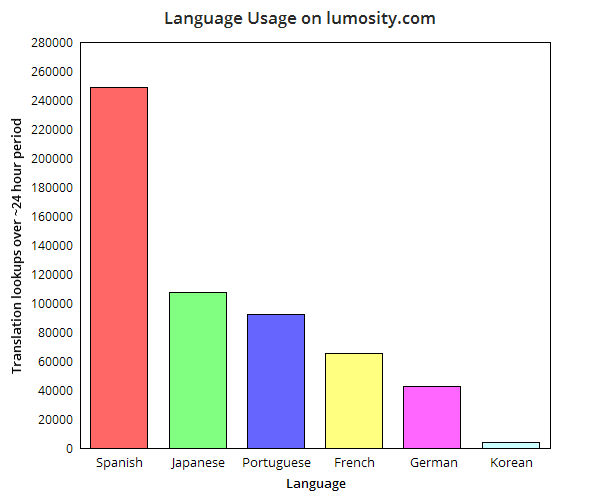
We also wanted to collect the data to possibly annotate the page each string is used on. Such information might help our translators by giving them more context, since a string’s location on a page can influence a translation substantially.
Fin
Well, that’s it! Happy localizing!